I was working on a program related to GCP and wanted to store some data.
It was a one-off piece of data that was not large enough to set up a database, nor was it likely to write a join query between the data.
To begin with, setting up a database was not an option because setting up a database would incur instance fees even when the database was not in use.
It seemed like a good idea to store the data in Google Cloud Storage, but Firestore seemed like it could be used for the same purpose, so we used Firestore this time.
I would like to continue to use Firestore easily, but Firestore is not as intuitive as Cloud Storege and requires some knowledge of Firestore to use, so I will note here how to use it.
What is Firestore?
Firestore, originally a Firebase database, is now offered as one of GCP's databases following Google's acquisition of Firebase.
Originally intended primarily for use with Firebase, it is suitable for storing data that is read and written frequently and in large volumes, such as data from web services.
Also, as a selling point of Firebase, it has an extensive JavaScript library for browsers, and Firestore can be handled directly from the browser without having to prepare a backend to handle Firestore, allowing web services to be built using only web apps.
Although Firestore has a strong impression of being a database for such web services, there is no problem in using it for reading and writing small amounts of data, as in this case.
Here, I would like to explain how to read and write such a small amount of data.
brief description
Firestore is a so-called key-value store, or NoSQL, which is more like a notepad that can be categorized into tiers than a database.
The contents of the notepad can store data in JSON as the user likes.
The contents of Firestore, like Cloud Storage, consists of Key (path) and actual file, and key is represented in a hierarchy of collection and document, which are described below, and JSON data is stored in the key location.
Introduction.
To understand Firestore, it is best to imagine a storage system such as Google Cloud Storage, AWS S3, or Azure Blob.
These storage locations consist of key and data, which indicate the location of the file.
At first glance, key appears to be a directory structure, like a file system, with directories nested within each other.
However, key is written to look like a directory structure, and key and data are one-to-one correspondence, and there is no such thing as a directory.
Firestore also looks like a directory structure, but like storage, key and data are one-to-one, not nested.
If you are aware of this mechanism, it will be easier to understand the behavior of Firestore.
configuration
document- It is like a file, where the data is finally stored. Like a file, it has a name.
collection- It is like an array that stores multiple
document.
- It is like an array that stores multiple
reference- The location of
documentandcollection, like the full path in a file.
- The location of
Example: Documentation
For example, to register a user from user to collection and a user from 123 to document, the following is used.
const ref = db.collection('user').doc('123'); await ref.set({ user_id: 123, user_name: "ABC", user_mail: "abc@exampble.com" });
db.collection('user').doc('123') is reference indicating the location of document, and data is written in set() at the location of reference.
It is not necessary to create collection or document in advance.
Example: Document acquisition
To obtain document, do the following
const ref = db.collection('user').doc('123'); const doc = await ref.get(); if( doc.exists ){ console.log(doc.data()); }
Create reference to indicate the location of document and change the reference to get().
Checks reference for the existence of document with .exist, and if it exists, retrieves the data stored with data().
Omit document name
In a typical database, when registering user data in the user table, only the data is registered.
However, in the case of Firestore, if collection of user corresponds to the user table, then the user data would be document of 123, and the document name 123 would need to be registered separately from the user data. The document name 123 must be registered separately from the user data.
Firestore is a key-value store, so it is natural that if you do not specify the name document for reference, which specifies user data, you cannot indicate where the document is located. However, if you want to treat Firestore like a database, it may be troublesome to generate and set up a non-overlapping document name each time.
In such cases, if you omit the name document when registering document, Firestore will automatically generate the document name without duplication.
If the document name is omitted, it will look like this
const ref = db.collection('user').doc(); // document name -> UOSnkhyz07BBwwcReeBL console.log(`document name -> ${ref.id}`); await ref.set({ user_id: 123, user_name: "ABC", user_mail: "abc@exampble.com" });
The auto-generated document name is stored in ref.id and becomes the name of document which is set() in reference.
To retrieve the registered document, do not use the document name, but use the query described below to retrieve the registered data.
const queryResult = db.collection('user').where('user_id', '==', 123).get(); if( !queryResult.empty ){ console.log(queryResult.docs[0].data()); }
level
The collection and document can be used in a hierarchy.
For example, to create a group loop for each collection of group and register the group user in it, the following is required.
const ref = db.collection('group').doc('groupA').collection('user').doc('123'); await ref.set({ user_id: 123 });
Again, collection and document do not need to be created in advance, and collection and document, which do not exist, can be used for reference.
path reference notation
In this way, we can see that reference is just a reference, like the full path in a file.
Looking at the above example as a file path, the user object could also be group/groupA/user/123. And indeed, you can specify reference in this way.
The above example, written in path of reference notation, would be as follows
const ref = db.doc('group/groupA/user/123'); await ref.set({ user_id: 123 });
Note on hierarchy Part 1
One thing to note about Firestore hierarchies is that collection and document can be in a hierarchy, but collection and document must be connected alternately.
It is not possible to create a hierarchy in which collection is followed by collection or document is followed by document.
This is inconvenient, but it is a Firestore rule, so we have no choice but to follow it. When using hierarchies, it is necessary to create the hierarchy so that object is exactly after collection.
Note on hierarchy Part 2
Another point to be aware of in the Firestore hierarchy is that even if you delete document in the upper hierarchy, document in the lower hierarchy will not be deleted and will remain.
Since the Firestore is a key value store, reference, which refers to document in the lower tier, is only key in its document, and the existence of document in its key, which is in the upper tier, is irrelevant to key. It is irrelevant whether or not the upper document in the key is real.
For example, the groupA document in the above example does not exist unless it is explicitly created with set().
However, document will remain if you delete it from the program. If you delete it from the GCP console, GCP will delete all object in the lower layer behind the scenes." If you want to remove collection and object from the upper layers, it is easy and recommended to remove them from the console of GCP.
Note on hierarchy Part 3
As mentioned at the beginning, storage like Google Cloud Storege appears to have directories and a nested structure, but in reality the directories do not exist and are not nested.
Firestore is similar, with collection, which appears to be nested, but in fact collection does not exist and is not nested.
It is just to describe collection in reference when generating document and make it look like object belongs in collection.
Therefore, it is not possible to create collection alone, but it is created in the process of generating object.
Similarly, collection cannot be deleted, and by deleting all document including its collection in reference, its collection will be deleted.
data update
Updating data is done by registering data with only the items to be updated set.
const ref = db.collection('user').doc('123'); await ref.update({ user_name: "XYZ", user_mail: "xyz@example.com" });
Points to note
Firestore updates the entered data items by overwriting them.
So, if the item was an array or object, it will be replaced by an array or object of entered data. In other words, you cannot add elements to the array or update only the items set in the object as they are.
To do so, it is necessary to use special functions or special writing methods, but I will not explain them here.
Personally, I think that if you are using it as a lightweight database replacement, you can update arrays and objects by retrieving the data once, updating the data, and then overwriting all the data in document.
query
To extract document from collection, use the query
The usage of the query is simple: just call the get() method of reference of collection.
By inserting where() or orderBy() in between, you can narrow down the search and set the order by conditions.
As a result of the query execution, the retrieved document is stored in the docs array.
let queryResult = await db.collection('user').get(); if( !queryResult.empty ){ queryResult.docs.forEach(doc=>consoel.log(doc.data())); } queryResult = await db.collection('user').where('user_name', '==', 'ABC').get(); if( !queryResult.empty ){ queryResult.docs.forEach(doc=>consoel.log(doc.data())); }
paging
Paging is performed when there are large numbers of query results, for example.
Paging is implemented by the user using startAfter(), limit() and orderBy().
let queryResult = await firestore.collection('user') .orderBy('user_id') .limit(2) .get(); while (!queryResult.empty) { const docs = queryResult.docs; docs.forEach((doc: any) => console.log(doc.data())); queryResult = await firestore.collection('user') .orderBy('user_id') .startAfter(docs[docs.length - 1]) .limit(2) .get(); }
startAfter() obtains document after the specified document.
Therefore, after clarifying the order with orderBy(), specify the number of pages to be retrieved with limit(), and for the second and subsequent pages, specify document as startAfter(), the last page retrieved in the previous session, and document as the next page to be retrieved.
Documentation that does not exist
As we have mentioned several times, document can be used with reference to specify a path where the upper layer document does not exist.
For example, in the following case, document can be created for 123 without creating document for groupA.
const ref = db.collection('group').doc('groupA').collection('user').doc('123'); await ref.set({ user_id: 123 });
When I look at this result in the GCP Firestore console, I see that groupA is shown, but it is italicized and the document does not exist.
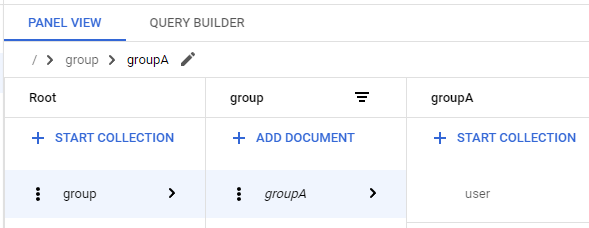
Let's add groupA to it.
const ref = db.collection('group').doc('groupA'); await ref.set({});
Then you can see that groupA is in the normal form and groupA exists.
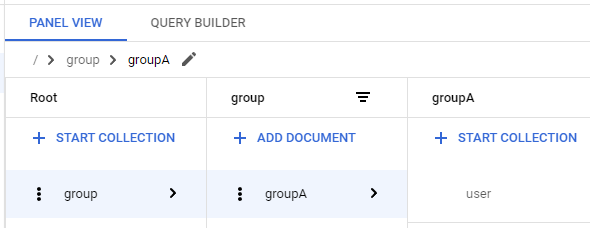
Now let's remove groupA.
const ref = db.collection('group').doc('groupA'); await ref.delete()
Then groupA is italicized again and groupA is deleted.
However, collection of user, which was under groupA, and document of 123, which was under user but not shown in the figure, were not deleted and remain.
Retrieve a document that does not exist
Normal queries cannot retrieve documents that do not exist.
To obtain a list of document directly under collection, including documents that do not exist, use listDocuments() in Referencing a Collection.
const ref = db.collection('group'); const docs = await ref.listDocuments(); docs.forEach(doc => console.log(doc.id)); // groupA
summary
Finally, I would like to write a snippet-like summary.
flow
It is recommended to be aware of the following flow from Document Reference to document and from Referencing a Collection to Array of documents.

Elements & Functions
Frequently used elements and functions in each class.
| class | Elements & Functions | summary |
|---|---|---|
| Document Reference | ||
| id | Document Name | |
| path | pass | |
| get() | Document Retrieval | |
| set() | Data addition/overwrite | |
| update() | data update | |
| delete() | deletion | |
| listCollections() | List of Collections | |
| document | ||
| exists | existence check | |
| id | Document Name | |
| ref | Document Reference | |
| createTime | Day of composition | |
| updateTime | Update Date and Time | |
| data() | data acquisition | |
| Referencing a Collection | ||
| id | collection name | |
| path | pass | |
| get() | query execution | |
| limit() | Number of pieces specified | |
| startAfter() | Retrieve the specified document or later | |
| where() | narrowing-down | |
| orderBy() | sort | |
| listDocuments() | List of documents owned (including documents that do not exist) |
sample code
Documentation
const ref = db.collection('user').doc('123'); await ref.set({ user_id: 123 });
const ref = db.collection('user').doc(); await ref.set({ user_id: 123 });
const ref = db.doc('user/123'); await ref.set({ user_id: 123 });
Document Retrieval
const ref = db.collection('user').doc('123'); const doc = await ref.get(); if( doc.exists ){ console.log(doc.data()); }
Documentation Update
const ref = db.collection('user').doc('123'); await ref.update({ user_data: 456 });
Delete Document
const ref = db.collection('user').doc('123'); await ref.delete();
query
const queryResult = await firestore.collection('user').get(); if( !queryResult.empty ){ for(const doc of queryResult.docs){ console.log(doc.data()); } }
paging
let queryResult = await firestore.collection('user') .orderBy('user_id') .limit(2) .get(); while (!queryResult.empty) { const docs = queryResult.docs; docs.forEach((doc: any) => console.log(doc.data())); queryResult = await firestore.collection('user') .orderBy('user_id') .startAfter(docs[docs.length - 1]) .limit(2) .get(); }
Impressions, etc.
I have used GCP's early Datastore in the past, and Firestore is easy to pick up compared to that.
At first, I was confused by the idea of a directory structure; if you think of Firestore as a directory structure, some of the behaviors seem strange, but if you think of it as a key-value store, it makes sense.
Firestore is convenient because you can suddenly write a path and store data there without the need for any previous preparation.
I will first use it as a place to store one-off data, like a notepad.