I have read Markdown, edited it in various ways as I wanted, and wanted to output it to Markdown again.
I used a JavaScript Markdown parser called remark.
However, it is difficult to understand how to use it, and I am sure I will forget how to use it the next time I need to modify the program, so I will leave it here as a reminder of how to use it this time.
configuration
Anyway, I was confused by the various related libraries that appeared, which made it difficult to grasp the whole picture. I am not sure where to begin, but I will start from the beginning.
What is it?
There is a project to create a framework to "create an AST tree (structure tree) from text (markup language), parse and transform the AST tree, and output it again to text (markup language).
The project is called unified.
unified is only a framework, and which markup language to read and which markup language to output is defined externally as a plugin.
The plugin remark is used to read Mardown to create an AST tree and to output Markdow from the AST tree.
Markdown is not the only markup language for which there are plug-ins; there are also HTML and XML. There are also plug-ins that convert Markdown AST trees to HTML AST trees and vice versa.
With them, the following processes can be performed using unified and various plug-ins.
- Create Markdown AST trees from Markdown text with plug-ins
- Convert Markdown AST tree to HTML AST tree with plugin
- Output from HTML AST tree to HTML text with plugin
With this series of processes, you can convert Markdown to HTML, and so on.
attention (heed)
As far as I could find, the only plug-ins for converting AST trees to another markup language AST tree were "Markdown to HTML" and "HTML to Markdown".
AST Wood
The base AST tree is unist.
The AST tree that extends unist to handle Markdown is mdast.
The AST tree that extends unist to handle HTML is hast.
AST Tree Utility
This was the case this time, but I may want to edit the AST tree myself.
In such cases, some common operations and convenient functions are provided under the name unist-util-....
How to use unified
The one that performs a series of processes is called processer, and by calling the execution function of processer, processer is made to perform the process.
What processer does will be built by adding plug-ins to processer. Plug-ins are added in .use(<plugin_name>).
The processer is divided into the following three parts
- Constructing an AST tree from text
Parser. - Deforming AST tree
Transformers. - Text output of AST tree
Compiler(stringify).
Each part is executed by the following functions of processer.
processer.parse()executesParserprocesser.run()executesTransformersprocesser.stringify()executesCompilerprocesser.process()does everything
Example
The following flow, plug-ins, and code are used to convert Markdown to HTML.
- Create Markdown AST tree from text (
remark-parse) - Convert Markdown AST tree to HTML AST tree (
remark-rehype) - Output HTML AST tree to text (
remark-stringify)
import { unified } from 'unified'; import remarkParse from 'remark-parse'; import remarkRehype from 'remark-rehype'; import remarkStringify from 'remark-stringify'; const processer = unified() .use(remarkParse) .use(remarkRehype) .use(rehypeStringify); const markdownText = fs.readFileSync('./data/in/sample.md'); const markdownTree = processer .parse(markdownText); const htmlTree = await processer .run(markdownTree); const htmlText = processer .stringify((htmlTree as any)); console.log(htmlText);
You can also use processer.process() to combine them into one.
const markdownText = fs.readFileSync('./data/in/sample.md'); const htmlText = await unified() .use(remarkParse) .use(remarkRehype) .use(rehypeStringify) .process(markdownText); console.log(htmlText);
Documentation of plugin options and how to avoid using unified
When you want to customize the behavior of a plugin, you set the plugin options, but the plugin is just the gauze, and another library does the implementation.
For example, the remark-parse plug-in is implemented by the mdast-util-from-markdown library.
As long as you know what libraries you are using, you can do the same thing without using unified and plug-ins.
import { fromMarkdown } from 'mdast-util-from-markdown'; import { toHast } from 'mdast-util-to-hast'; import { toHtml } from 'hast-util-to-html' const markdownText = fs.readFileSync('./data/in/sample.md'); const markdownTree = fromMarkdown(markdownText); const htmlTree = toHast(markdownTree); const htmlText = toHtml(htmlTree); console.log(htmlText);
Documentation of plugin options
The documentation for the options is not on the plugin page, but on the library page.
So, we first need to know which libraries the plug-ins use.
You can find out which libraries the plugin uses by carefully reading the library documentation, but if you still cannot find it, look at index.js in the source of the plugin to see what libraries it imports.
AST Tree Analysis
Describes how to analyze and transform the generated AST tree.
The output AST tree is a JavaScript Object.
In a simplified explanation, a basic node is defined by unist. A basic node consists of an type array that represents the type and an children array that stores the child nodes.
interface Node { type: string; }; interface Parent extends Node { chilren: Node[] };
The AST trees of each markup language then extend this basic form, each with its own elements.
Since it is a JavaScript object, you are free to parse and transform it as you like, but to make your work easier, a traversing utility unist-util-visit is provided.
traverse
Passing an AST tree to unist-util-visit will invoke the specified function on all nodes.
nodecurrent nodeparentparent node- Position of the children of the current
indexnode as seen from the parent node.
import { visit } from 'unist-util-visit' visit(tree, (node, index, parent) => { console.log(node); });
revision
The node's data can be modified during traversal.
Note that unist-util-visit is not Immutable, but modifies the input AST tree.
visit(tree, (node, index, parent) => { if (node.type === 'text') { if (node.value) { node.value = 'TEST'; } } });
deformation
You can also traverse a node and "delete," "add," or "merge" its children. Note that, as before, unist-util-visit is not Immutable, but modifies the input AST tree.
The traverses are performed in the following order
- myself
- child
- Next sibling
For example, in the figure below, the nodes are called in the order A - B - D - F - G - E - C.
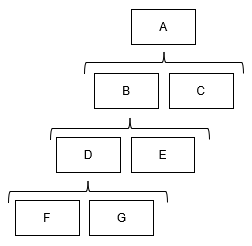
Points to note
Instead of the parent manipulating the children array, the child manipulates the parent's children array and uses Array.slice() to manipulate the children array.
Example
To delete the type node from the text node, do the following
import { visit, SKIP, CONTINUE } from 'unist-util-visit'; visit(tree, (node, index, parent) => { if (node.type === 'text') { parent.children.slice(index, 1); return [SKIP, index]; } });
The meaning of return is explained next.
Next node to traverse
With return you can change the order of subsequent traverses." Without return, traverses are performed according to the normal rules.
Sub-designation
Normally, the next node to be traversed is the child node, but if SKIP is set as the first node in the return array, the child node will not be traversed.
In the previous example, since we are deleting our own node, we specify SKIP to prevent our child nodes from being traversed.
If CONTINUE is specified, your child node will be traversed.
Brother Designation
After the traversal of its own child node and its descendant nodes is completed, the sibling nodes are traversed, and the position of the sibling is specified in the second array of return.
The position is the index of the children array in the parent.
If you delete your node or merge it with a sibling node, the position of your next sibling will change, so you specify here that the next sibling you are supposed to traverse will not be skipped.
In the previous example, since we deleted our node, the next sibling is index where we used to be, so we return that value.
There is no need for value checking, since it is not an error if the index value exceeds the actual number of children.
Home-made plug-ins
The part of the coding that would be implemented uniquely would be the parsing and deformation part of the AST tree.
By combining this part into a function that takes tree as its first argument and file as its second argument, the implementation can be made into a plugin.
function myPlugin(): any { return (tree: any, file: any) => { visit(tree, (node, index, parent) => { if (node.type === 'text') { node.value = 'TEST'; } }); }; } const outText = await unified() .use(remarkParse) .use(myPlugin) .use(remarkStringify) .process(inText);
Impressions, etc.
I was talking about the use of remark, but I ended up talking about unified and unist.
In fact, the bottlenecks in using remark are "understanding the overall picture of unified", "AST tree operations", and "how to investigate the libraries used inside the plug-in and their options", so we have focused on these issues.
To customize the plugin, you have to set options, but it is quite a hassle to get to the documentation.
Also, it is not possible to determine what a plugin does just by looking at it.
For example, use the remark-gfm plugin to parse and output GitHub Flavored Markdown(GFM).
Then, the code to create a GFM AST tree from the text GFM and output the text GFM again using unified would be as follows.
import { unified } from 'unified'; import remarkParse from 'remark-parse'; import remarkStringify from 'remark-stringify'; import remarkGfm from 'remark-gfm'; const outGfmText = await unified() .use(remarkParse) .use(remarkGfm) .use(remarkStringify) .process(inGfmText);
This is handled internally as follows
import { fromMarkdown } from 'mdast-util-from-markdown'; import { gfm } from 'micromark-extension-gfm' import { gfmFromMarkdown, gfmToMarkdown } from 'mdast-util-gfm' import { toMarkdown } from 'mdast-util-to-markdown'; const gfmTree = fromMarkdown(inGfmText, { extensions: [gfm()], mdastExtensions: [gfmFromMarkdown()], }); const outGfmText = toMarkdown(gfmTree, { extensions: [gfmToMarkdown()], });
The remarkGfm plugin adds GFM-related extensions to parse and strigify. The options in the remarkGfm plugin are passed on to its GFM-related extension options, so you will need to refer to the documentation of the GFM-related extension options to know what the options in the remarkGfm plugin mean.
So, if you want to use a plugin, you need to actually look at the source to understand what it does, find out what libraries are used in it, and then go to the library page to see the documentation.
This process is super tedious!
At first, I wrote the program according to the unified method, but as I wrote and tested the program using only the library to check the behavior of the options, it became troublesome to go back to the plug-in, and I ended up using only the library instead of unified.
Finally, we will summarize the relationship between the various conversions, plug-ins, and libraries used for reference.
| from | to | plugin | library |
|---|---|---|---|
| Text | Markdown AST | remark-parse | mdast-util-from-markdown |
| Markdown AST | Text | remark-stringify | mdast-util-to-markdown |
| Text | GFM Markdown AST | remark-gfm | mdast-util-gfm micromark-extension-gfm |
| GFM Markdown AST | Text | remark-gfm | mdast-util-gfm |
| Text | Html AST | rehype-parse | hast-util-from-parse5 |
| Html AST | Text | rehype-stringify | hast-util-to-html |
| Markdown AST | Html AST | remark-rehype | mdast-util-to-hast |
| Html AST | Markdown AST | rehype-remark | hast-util-to-mdast |